
本文来源吾爱破解论坛
本帖最后由 fatcat01 于 2020-2-5 16:08 编辑
运行平台: Windows
Python版本: Python3.6
IDE: PyCharm
其他工具:Chrome浏览器
[TOC]
1.寻找词典来源作为一个程序员,会经常查阅一些技术文档和技术网站,很多都是英文的,遇到不认识的词就要查,词典的使用频率也颇高,既然是程序员,高逼格的方式当然是做一个词典,此为动机。
我寻找一个好的词典的标准是:解释到位、数据抓取方便。
几个候选词典有:百度翻译、金山词霸、有道翻译、谷歌翻译。
最终选定金山词霸作为词源,原因:
大学时就使用金山词霸; url比较简单。 2.数据抓取 2.1 寻找URL 打开金山词霸在线翻译首页http://www.iciba.com/ ,输入一个单词进行查询,此处以“call”为例,查询页面出来以后看URL,浏览器的地址栏内容为http://www.iciba.com/call 。猜想查询URL格式为http://www.iciba.com/ 后面跟上要查询的单词(或词语),将call改为其他单词果然跳出相应的查询页面,中文也一样,由此可以证明以上猜想,也可以看出查询的URL真的简单明了。
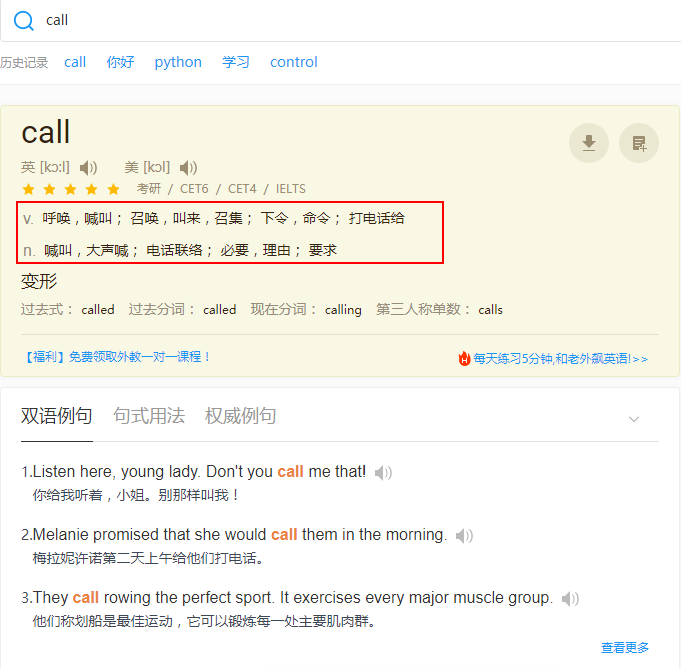
2.2 寻找数据 我只是想弄懂单词的意思,所以我需要的数据是如图所示部分:
在浏览器按F12键调出开发者工具,然后刷新页面,我们要在页面中寻找我们需要的数据,按图示操作:
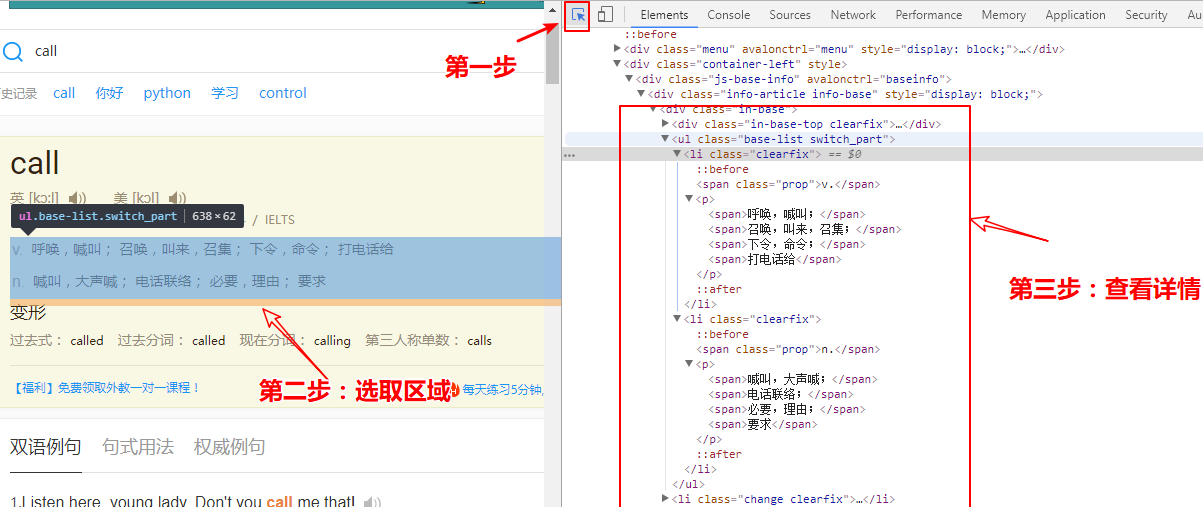
确定好了数据区域是< ul class="base-list switch_part">和< /ul>中间的部分,接下来就把这些数据都抓取下来吧。
2.3 抓取数据 抓取数据用到了urllib.request库,解析html用到了BeautifulSoup库。所以首先导入这两个库。
import urllib.request
from bs4 import BeautifulSoup 需要将整个网页内容抓取下来,用如下代码实现:
root_url = 'http://www.iciba.com/'
word = input('请输入想要查询的单词(或"q"退出):\n')
url = root_url + word # 拼接URL
response = urllib.request.urlopen(url)
html = response.read() 有了html内容,接下来要把 base-list switch_part 标签里的内容读取出来,BeautifulSoup里的find可以实现此功能:
soup = BeautifulSoup(html, 'lxml')
tag_soup = soup.find(class_='base-list switch_part')
print(tag_soup) 获得输出结果为:
<li class="clearfix">
<span class="prop">v.</span>
<p>
<span>呼唤,喊叫;</span>
<span>召唤,叫来,召集;</span>
<span>下令,命令;</span>
<span>打电话给</span>
</p>
</li>,
<li class="clearfix">
<span class="prop">n.</span>
<p>
<span>喊叫,大声喊;</span>
<span>电话联络;</span>
<span>必要,理由;</span>
<span>要求</span>
</p>
</li> 可以看出里面包含了两个< li class="clearfix">< /li>,这表明call这个单词有两个词性,接下来就要解析出所有的词性,用到BeautifulSoup的find_all函数:
meanings = tag_soup.find_all(class_='clearfix')
for i in range(len(meanings)):
translation = meanings[i].get_text() # 获取文本内容
print(translation.strip()) # 去掉字符串开头和结尾的空行
print('='*30) # 华丽的分割线 最后输出结果如图所示,这已经是我想要的结果了。

该词典的的基本功能已经完成,但是存在几个缺陷。
3.1 查询中文 查询英语单词已经没有问题了,那么查询中文试试:
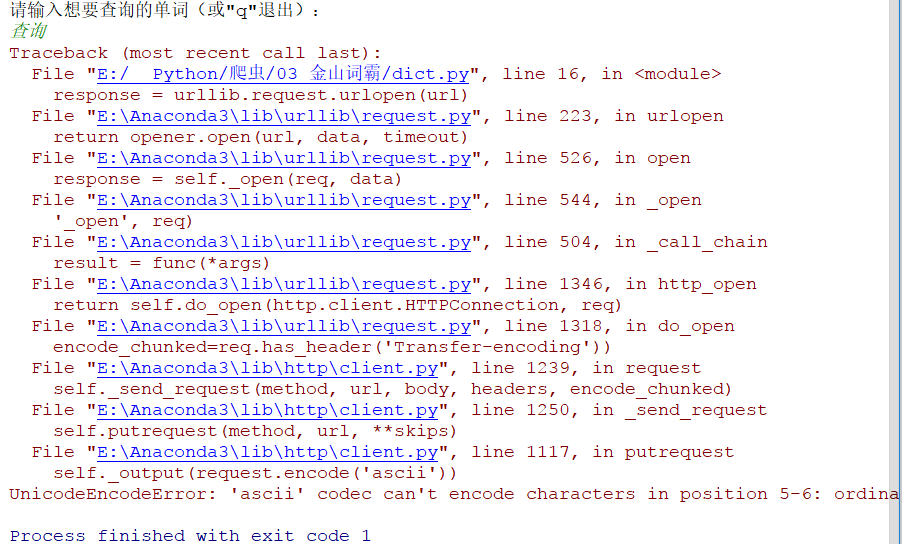
程序报错,是编码问题,是urllib.request.urlopen函数导致的,我们只需将URL拼接改为url = root_url + urllib.parse.quote(word)即可,试一下:

如果查询不存在的单词结果会如何:
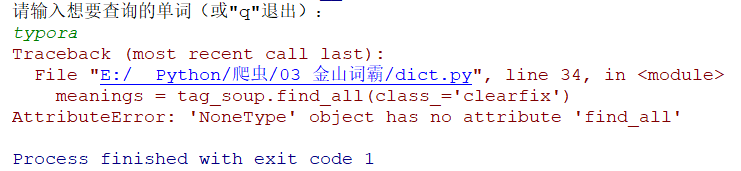
失败是因为在tag_soup = soup.find(class_='base-list switch_part')这一行执行完之后,tag_soup的值为None,已经不是BeautifulSoup里的数据类型了,已经不能使用find_all 函数了。那么在此处做一个判断:
if tag_soup == None: # 防止输入的单词没有释义
print(Fore.GREEN + '输入的单词不存在,重新输入.')
else:
meanings = tag_soup.find_all(class_='clearfix')
for i in range(len(meanings)):
translation = meanings[i].get_text()
print(ranslation.strip()) # 去掉字符串开头和结尾的空行
print('='*30) 为了可以循环查询,将用户输入、查询、显示的步骤放到while True:语句里,那么如何优雅的退出呢?判断输入,我以字母‘q’为退出标识。
while True:
word = input('请输入想要查询的单词(或"q"退出):\n')
if word == 'q':
break
else:
......(解析和显示工作) 这个工具是要自己使用的,最终是在控制台下显示,一团黑白相间的东西,没有美感,那么如何美化输出呢?将输出染上颜色。
控制台输出上色需要用到colorama第三方库,使用pip进行安装:
pip install colorama 引入该库:
from colorama import init,Fore # init是初始化,Fore是字体颜色
init(autoreset=True) # 初始化 将几个print语句进行上色:
print(Fore.GREEN + '输入的单词不存在,重新输入.')
......
print(Fore.CYAN + translation.strip())
print(Fore.RED + '='*30) 来看一下最终效果:
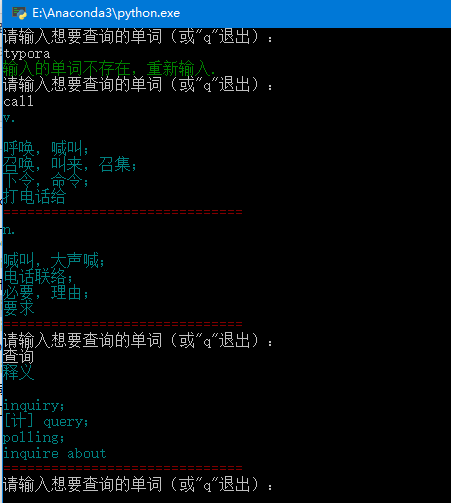
至此,一个简单的词典就完成了。
4. 如何使用 4.1 直接运行py文件如果你已经开发完此词典说明你电脑里已经有python环境了,那么可以直接运行py文件。
我已经将py文件的打开应用设置为python.exe了,所以可以直接双击运行。 打开cmd,进入该py文件目录,执行python dict.py即可运行。
4.2 打包
如果要给别人使用,那么打包成exe就是个完美的解决方案了。打包用到了pyinstaller第三方库,执行pip install pyinstaller进行安装。此处打包用到了pyinstaller的两个参数:
到网上去下载一个ico文件作为改程序的图标(程序员也是要美感的),推荐一个icon下载网站http://www.easyicon.net/ 。打开CMD,进入到dict.py所在文件夹执行如下指令:
pyinstaller -F -i Dictionary.ico dict.py 在dist目录下就可以看到生成的exe了。把dict.exe放到某个目录下,将快捷方式放到桌面,或者将该目录放到系统环境变量中,在cmd下直接敲dict.exe就能运行了,酷!
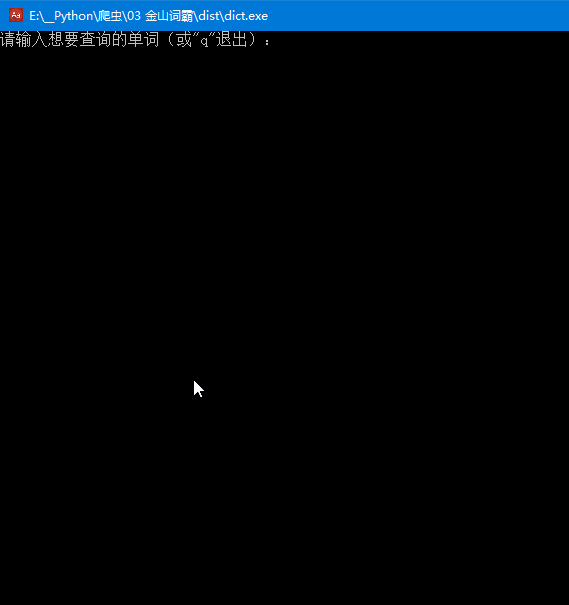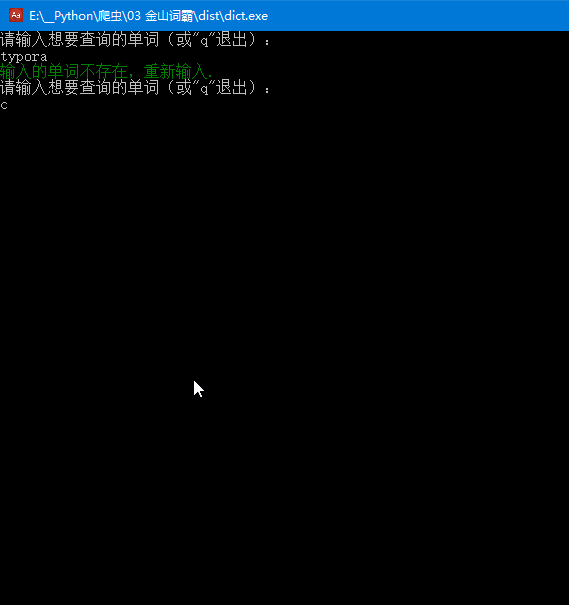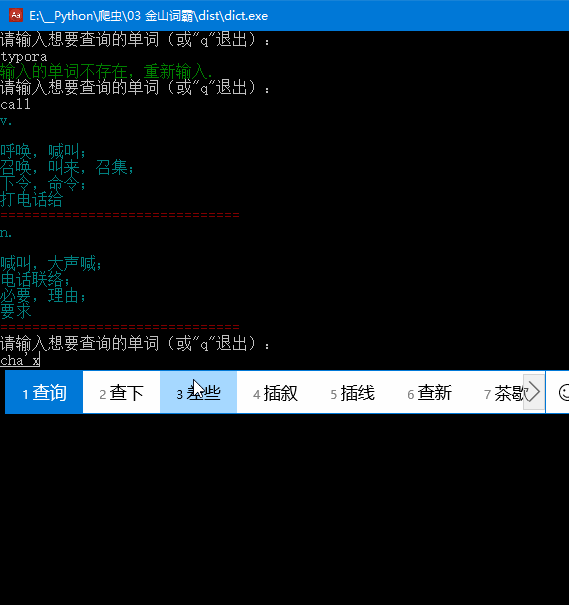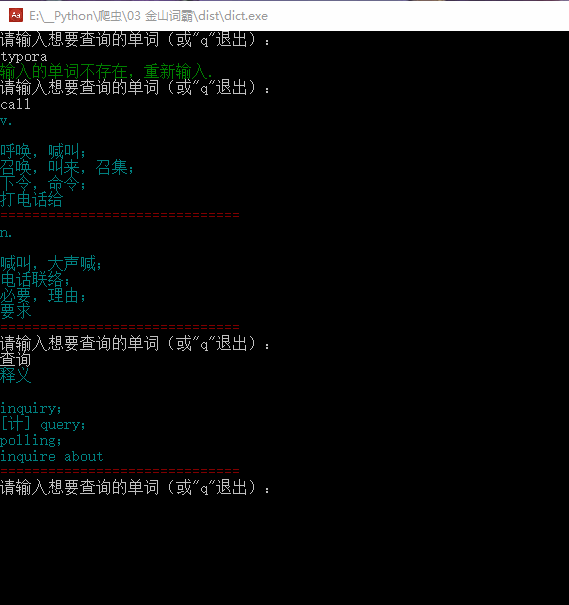
欣赏一下最终效果:
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 16 2017
@author: WangQiang
"""
import urllib.request
from bs4 import BeautifulSoup
from colorama import init,Fore
init(autoreset=True)
root_url = 'http://www.iciba.com/'
while True:
word = input('请输入想要查询的单词(或"q"退出):\n')
if word == 'q':
break
else:
url = root_url + urllib.parse.quote(word) # 解决url中带有中文编译失败的问题
response = urllib.request.urlopen(url)
html = response.read()
soup = BeautifulSoup(html, 'lxml')
tag_soup = soup.find(class_='base-list switch_part')
if tag_soup == None: # 防止输入的单词没有释义
print(Fore.GREEN + '输入的单词不存在,重新输入.')
else:
meanings = tag_soup.find_all(class_='clearfix')
for i in range(len(meanings)):
translation = meanings[i].get_text()
print(Fore.CYAN + translation.strip()) # 去掉字符串开头和结尾的空行
print(Fore.RED + '='*30)下载链接:链接:https://pan.baidu.com/s/16OlPqZjf4735OJOGHZyzeg 提取码:iin4
版权声明:
本站所有资源均为站长或网友整理自互联网或站长购买自互联网,站长无法分辨资源版权出自何处,所以不承担任何版权以及其他问题带来的法律责任,如有侵权或者其他问题请联系站长删除!站长QQ754403226 谢谢。
- 上一篇: B站弹幕云python源码
- 下一篇: 学习Python分享——自助结算







评论