
这篇文章主要介绍了Pandas分组与排序的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
一、pandas分组
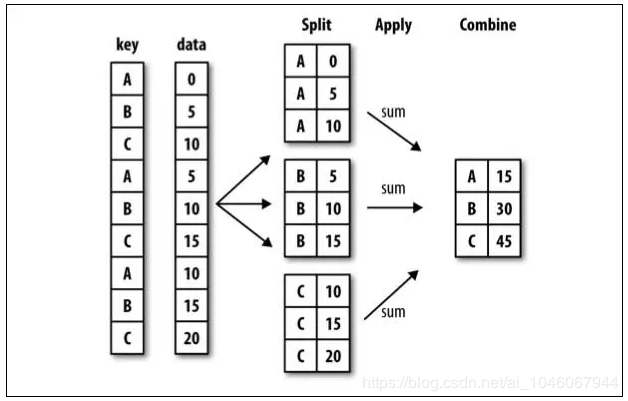
1、分组运算过程:split->apply->combine
- 拆分:进行分组的根据
- 应用:每个分组运行的计算规则
- 合并:把每个分组的计算结果合并起来
2、分组函数
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False, **kwargs
by: 依据哪些列进行分组,值可以是:mapping, function, label, or list of labels
3、聚合函数

4、分组聚合实例
单列分组
>>> import pandas as pd
>>> df = pd.DataFrame({'A': ['a', 'b', 'a', 'c', 'a', 'c', 'b', 'c'], 'B': [2, 8, 1, 4,
3, 2, 5, 9], 'C': [102, 98, 107, 104, 115, 87, 92, 123], 'D': [2, 98, 17, 14, 15, 7, 92,
13]})
>>> df
A B C D
0 a 2 102 2
1 b 8 98 98
2 a 1 107 17
3 c 4 104 14
4 a 3 115 15
5 c 2 87 7
6 b 5 92 92
7 c 9 123 13
>>> df.groupby(by='A').sum()
B C D
A
a 6 324 34
b 13 190 190
c 15 314 34
多列分组
>>> df.groupby(by=['A','B']).sum() ###A,B成索引
C D
A B
a 1 107 17
2 102 2
3 115 15
b 5 92 92
8 98 98
c 2 87 7
4 104 14
9 123 13
多列聚合
>>> df.groupby(by=['A','B'])['C'].sum() ###1个列
A B
a 1 107
2 102
3 115
b 5 92
8 98
c 2 87
4 104
9 123
>>> df.groupby(by=['A','B'])['C','D'].sum() ###2个列
C D
A B
a 1 107 17
2 102 2
3 115 15
b 5 92 92
8 98 98
c 2 87 7
4 104 14
9 123 13
多列不同聚合方式
>>> import numpy as np
>>> df.groupby(by=['A']).agg({'C':[np.mean, 'sum'], 'D':['count',np.std]})
C D
mean sum count std
A
a 108.000000 324 3 8.144528
b 95.000000 190 2 4.242641
c 104.666667 314 3 3.785939
>>>ps: 不同列使用多个不同函数进行聚合C: mean,sum;D:count,std
返回值类型区别
方法1:agg
>>> df.groupby(by=['A']).agg({'C':[np.mean]})
C
mean
A
a 108.000000
b 95.000000
c 104.666667
>>> type(df.groupby(by=['A']).agg({'C':[np.mean]}))
<class 'pandas.core.frame.DataFrame'>
方法2:索引
>>> df.groupby(by=['A'])['C'].mean()
A
a 108.000000
b 95.000000
c 104.666667
Name: C, dtype: float64
>>> type(df.groupby(by=['A'])['C'].mean())
<class 'pandas.core.series.Series'>
总结: 两种方法结果一样,但是一个类型是DataFrame,一个为Series;有时候会用上
二、pandas排序
按索引进行降序排列
>>> df A B C D 0 a 2 102 2 1 b 8 98 98 2 a 1 107 17 3 c 4 104 14 4 a 3 115 15 5 c 2 87 7 6 b 5 92 92 7 c 9 123 13 >>> df.sort_index(ascending=False) ### 索引 A B C D 7 c 9 123 13 6 b 5 92 92 5 c 2 87 7 4 a 3 115 15 3 c 4 104 14 2 a 1 107 17 1 b 8 98 98 0 a 2 102 2
按值进行降序排列
>>> df.sort_values(by="A",ascending=False) # 按某一列 A B C D 3 c 4 104 14 5 c 2 87 7 7 c 9 123 13 1 b 8 98 98 6 b 5 92 92 0 a 2 102 2 2 a 1 107 17 4 a 3 115 15 >>> df.sort_values(by=["B","A"],ascending=False) # 按2列 A B C D 7 c 9 123 13 1 b 8 98 98 6 b 5 92 92 3 c 4 104 14 4 a 3 115 15 5 c 2 87 7 0 a 2 102 2 2 a 1 107 17
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
版权声明:
本站所有资源均为站长或网友整理自互联网或站长购买自互联网,站长无法分辨资源版权出自何处,所以不承担任何版权以及其他问题带来的法律责任,如有侵权或者其他问题请联系站长删除!站长QQ754403226 谢谢。








评论